Checksum is a standard practice among DBAs to verify the data consistency across replicated nodes. In this post we’re going to review the syncing options for an inconsistent MySQL slave of Galera cluster node.
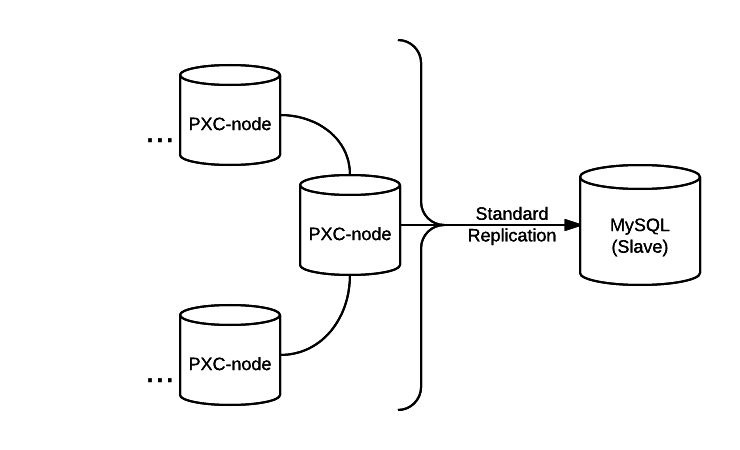
Here we’re assuming a setup of regular replication to a MySQL instance from one of the Galera cluster nodes.
In the usual MySQL replication setup, standard practice involves the usage of the pt-table-checksum tool to identify the discrepancies and usage of pt-table-sync to bring them in sync. The checksum tool, pt-table-checksum, can run across Galera cluster node to verify the data consistency and confirm if the MySQL slave is consistent with a chosen primary node.
What happens if this Galera cluster’s regular MySQL slave sees data inconsistency on it? Will pt-table-sync work there? The answer to this depends…
pt-table-sync when used with –sync-to-master causes it to take locks on master but Galera doesn’t like those lock attempts.
You may ask, why locks on a master?
Coz’ pt-table-sync will treat the master as the source and the slave as the destination. It will lock the table (–lock=1) on master, apply changes on master which will eventually be replicated to slave and thus causing the sync.
Respective snippet of code from pt-table-sync script V.2.2.15:
lock_server(src => $src, dst => $dst, %args);
...
$exit_status |= sync_a_table(
src => $src,
dst => $dst,
where => 1, # prevents --where from being used
diff => $diff,
%args,
);
...
unlock_server(src => $src, dst => $dst, %args);
Again… coming back to our point, pt-table-sync wouldn’t work well on Galera with –sync-to-master. Let’s do an attempt:
PTDEBUG=1 ./pt-table-sync --verbose --execute --replicate=pyth.checksum --sync-to-master --tables slave_repl.tmp h=localhost,u=root,p=$pw > slave_repl.tmp.sql
If you run the above command (on slave) with debug you will note following error:
# TableSyncer:6114 4650 Committing DBI::db=HASH(0x177cf18) Deadlock found when trying to get lock; try restarting transaction at line 6115 while doing slave_repl.tmp on localhost
(without PTDEBUG you won’t see much on slave except it will report nothing changed!)
Great, so why the error? Let’s again check the code snippet (pt-table-sync V.2.2.15):
sub lock_table {
my ( $self, $dbh, $where, $db_tbl, $mode ) = @_;
my $query = "LOCK TABLES $db_tbl $mode";
PTDEBUG && _d($query);
...
As you see, it’s calling up for LOCK TABLES and Galera, which as we know, doesn’t support explicite locking because of the conflict with multi-master replication. That’s the reason for the error above.
Okay, let continue… Upon executing pt-table-sync on slave, the “master”‘s (Galera node’s) error-log will show the following error:
2015-08-27 14:45:07 6988 [Warning] WSREP: SQL statement was ineffective, THD: 17, buf: 1399 QUERY: commit => Skipping replication
We already have a bug report in place and if it affects you, go ahead and mark it so.
So how would you fix this?
Easy Answer: Do a complete rebuild of slave from a fresh data backup of the cluster node.
Desync the cluster node, take the backup and restore it on a slave machine and setup replication.
But let’s think about an alternate method other than a complete restore…
“fixing using pt-slave-restart?”
But pt-table-sync is “not Galera Ready” as they say!!
Even then, pt-table-sync can help us understand the differences and that’s the long answer 🙂
It can still work and prepare SQL for you using –print –verbose options.
./pt-table-sync --verbose --print --replicate=pyth.checksum --sync-to-master --tables slave_repl.tmp h=localhost,u=root,p=$pw > slave_repl.tmp.sql
So, all you need to do is run the SQL against a slave to fix the discrepancies. You may choose to desync the node and run the pt-table-sync to generate differential sql. You’ll still need to confirm if slave got synced by re-running the pt-table-checksum and the discrepancies are resolved.
Our steps to resync a PX Cluster’s slave using pt-table-sync are as follows:
(Note: It’s advisable to stop writes on cluster to fix the discrepancies on slave. “Why?” “Explained later.”)
– Desync master node:
set global wsrep_desync=ON;
– Generate differential SQL:
./pt-table-sync --verbose --print --replicate=pyth.checksum --sync-to-master --tables slave_repl.tmp h=localhost,u=root,p=$pw > slave_repl.tmp.sql
– Review the sql generated and execute them on slave.
– Once slave is synced, you can:
set global wsrep_desync=OFF;
– Finally rerun the pt-table-checksum to verify the discrepancies.
That concludes our solution.
“Wait, but why desync?”
hmm… Well wsrep_desync is a dynamic variable which controls whether the node can participate in Flow Control.
“hold on!! Flow control??”
Galera has synchronous replication where in node provides the feedback to rest in the group – fellas-I’m-late-hold-on OR okay-let’s-continue-the-job. So this communication feedback is flow control. (You should read galera-documentation & Jay’s post).
When we will set wsrep_desync=ON on master, it will continue to replicate in and out the writesets as usual; but flow control will no longer take care of the desynced node. So, other nodes of the group won’t bother about the deynced node lagging behind. Thus by desyncing we’re making sure that our operations on one node are not affecting the whole cluster. This should answer why writes need to be stopped before starting to sync.
Hope this helps.
PS: This blog was published on Pythian Blog.