
In this podcast, we’ll explore the issue of duplicate indexes in MySQL; including redundant index, foreign keys, left-prefixed secondary index /w primary key, and how to tackle the issue at hand.
Earlier last week I happened to note a conversation on he following recommendation of pt-online-schema-change for the removal of duplicate keys.
# Key secondary_mysql_index ends with a prefix of the clustered index
# Key definitions:
# KEY `secondary_mysql_index` (`column_name`,`id`),
# PRIMARY KEY (`id`),
# Column types:
# `column_name` bigint(20) unsigned not null
# `id` bigint(20) unsigned not null auto_increment
# To shorten this duplicate clustered index, execute:
ALTER TABLE `database_name`.`table_name` DROP INDEX `secondary_mysql_index`, ADD INDEX `correct_secondary_index` (`column_name`);What it says is:
- KEY
secondary_mysql_index(secondary_id,id) is having prefix of the clustered index. That is prefix of the Primary Key. By default Primary Key is automatically added towards the end of the leaf node of secondary index. That’s why it is flagged for adjustment. - So, the tool is suggesting to do two things:
- DROP INDEX
secondary_mysql_index-> dropping this unnecessary overhead of explicitly adding a Primary Key - ADD INDEX
correct_secondary_index(column_name); -> Ensuring the secondary index still remains
Listen to Duplicate indexes in MySQL and more
Images for Duplicate Indexes in MySQL





What are duplicate indexes and how do they impact MySQL performance?
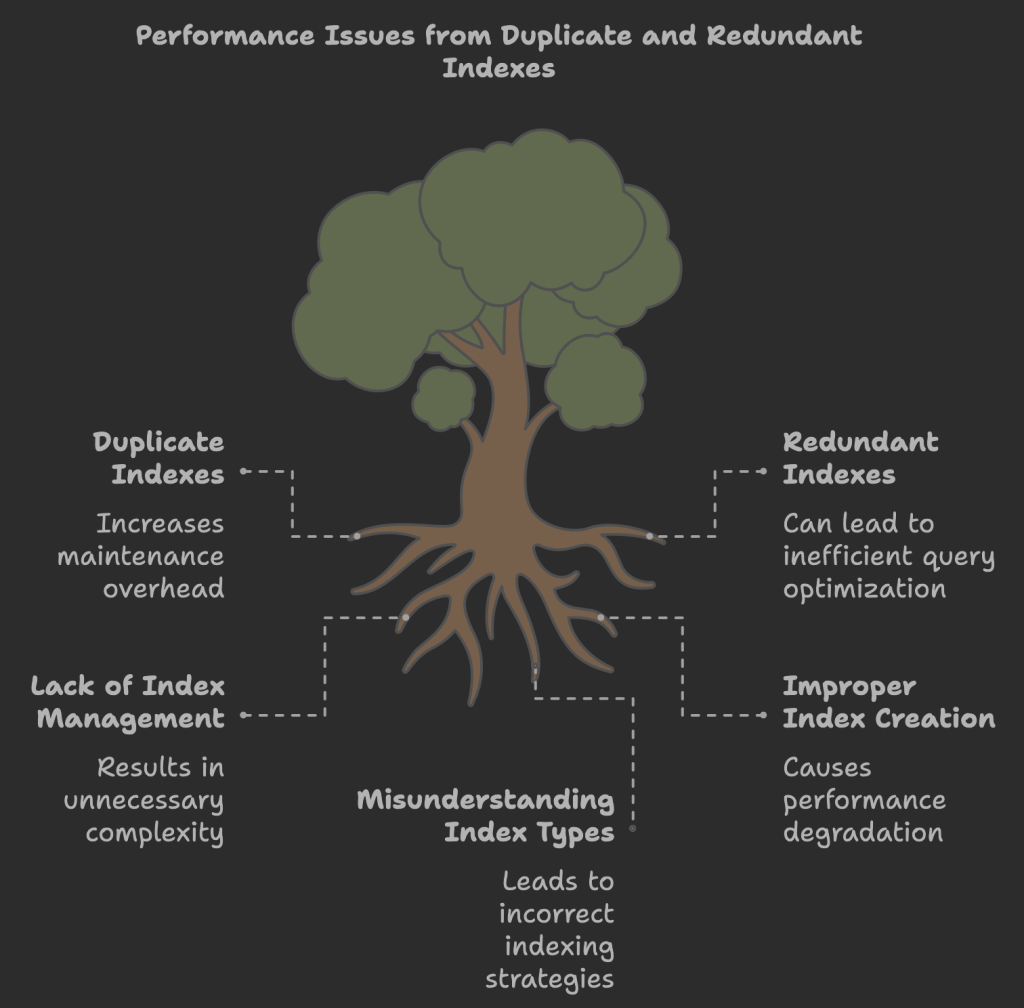
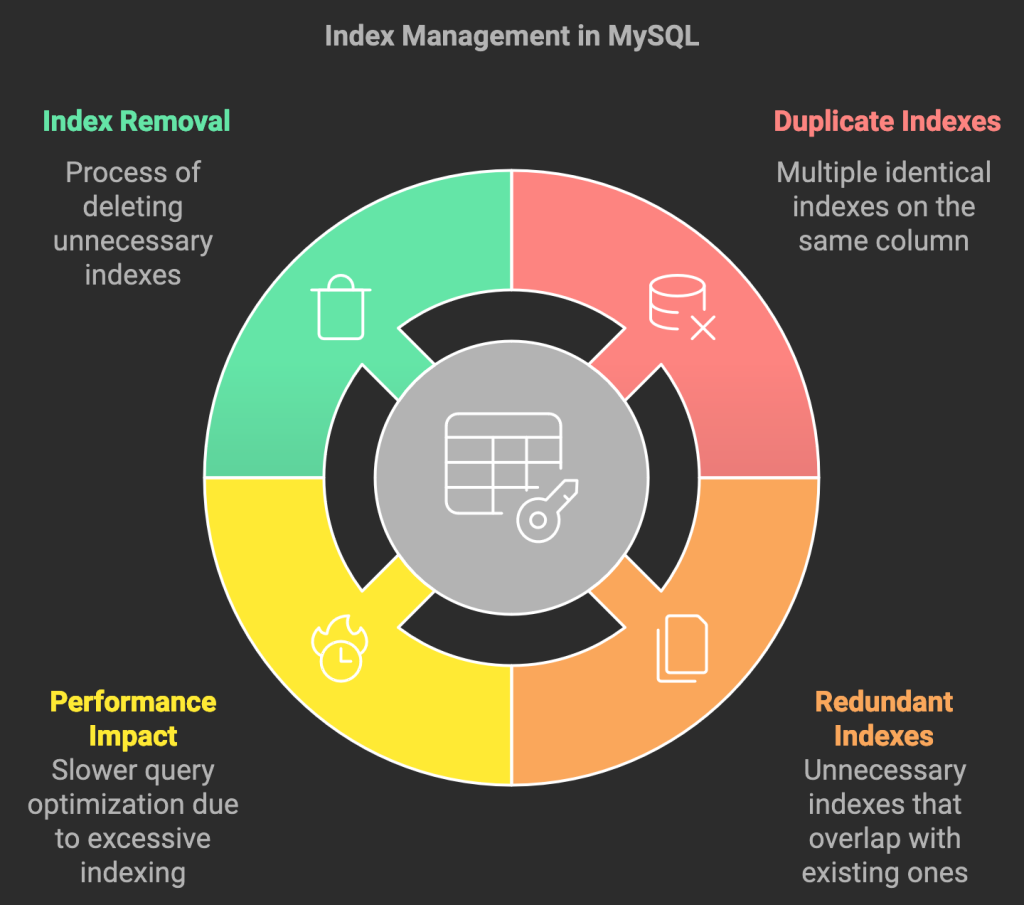
Duplicate indexes occur when a table has multiple indexes defined on the same columns. This can involve indexes with different names or different keywords used in their definition. For instance, having a PRIMARY KEY(id), UNIQUE KEY id(id), and KEY id2(id) is redundant. A single PRIMARY KEY suffices as it enforces uniqueness and can be utilized in queries.
Duplicate indexes negatively impact MySQL performance because the database must maintain each duplicate index separately. This increases storage space consumption and slows down data modification operations (insert, update, delete).
What are redundant indexes and how do they differ from duplicate indexes?
Redundant indexes are B-Tree indexes that are prefixes of other indexes. For example, having KEY(A), KEY(A,B), and KEY(A(10)) includes redundant indexes because the first and last are prefixes of KEY(A,B).
Unlike duplicate indexes, which should almost always be removed, redundant indexes can sometimes be beneficial. If the longer index is significantly larger, using the shorter, redundant index might be faster for certain queries.
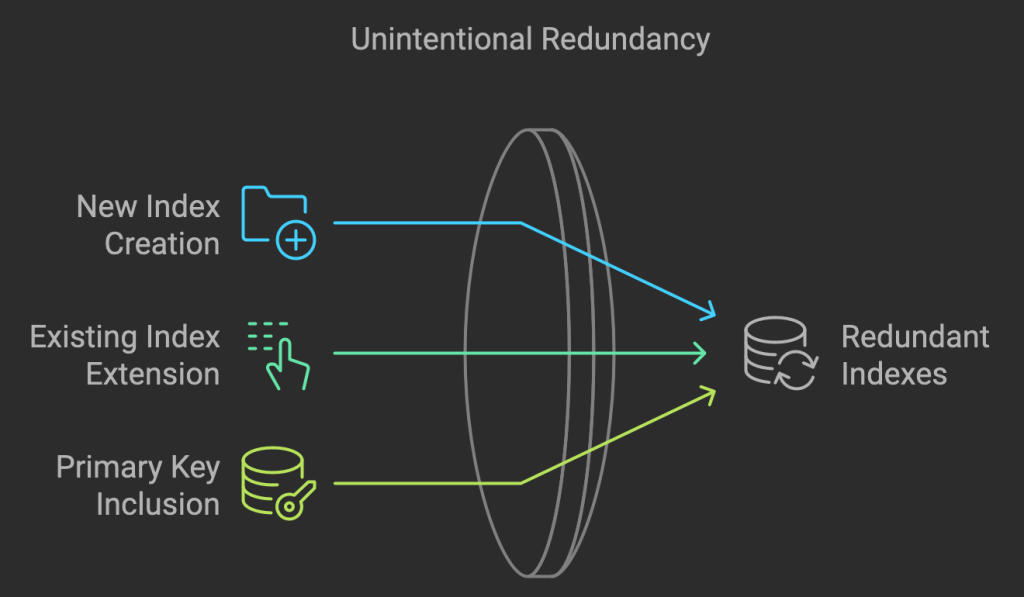
Why might someone create redundant indexes?
Redundant indexes often appear unintentionally. Someone might add a new index on (A,B) instead of extending an existing index on (A) to include B. Another scenario is adding an index on (A, ID) where ID is the primary key, which is already included in InnoDB tables.
Are there situations where keeping redundant indexes is beneficial?
Yes, there are cases where a shorter, redundant index can outperform a longer index. This typically occurs when the longer index is very large. For example, if A is an integer and B is a varchar(255) holding long values, using KEY(A) might be significantly faster than KEY(A,B) for queries filtering only on A.
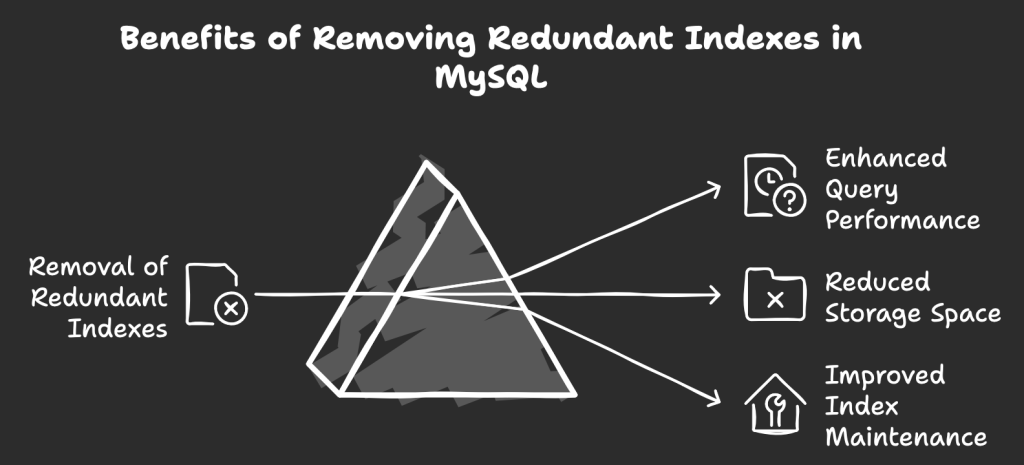
What are the benefits of removing duplicate and redundant indexes?
Removing unnecessary indexes provides several advantages:
- Enhanced query performance: Fewer indexes simplify the query optimizer’s decision-making process, leading to faster query execution.
- Reduced storage space: Dropping unused indexes frees up disk space for more valuable data.
- Improved index maintenance: Managing fewer indexes makes maintenance tasks simpler and faster.
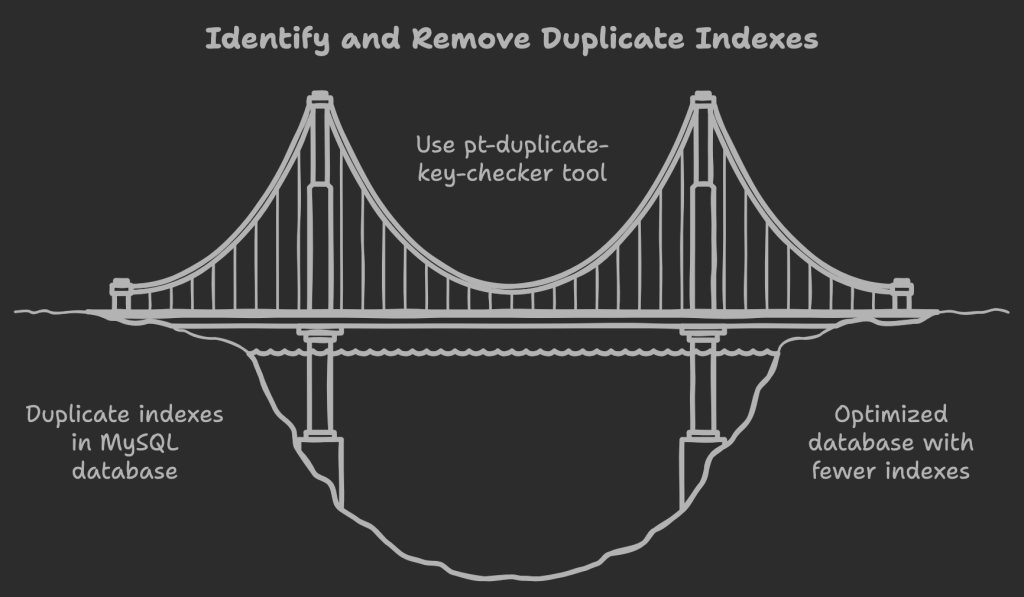
How can I identify duplicate and redundant indexes in my MySQL database?
The pt-duplicate-key-checker tool from the Percona Toolkit is a valuable resource for identifying duplicate and redundant indexes. It analyzes indexes, foreign keys, and composite keys to detect various redundancy issues.
How can I safely remove duplicate and redundant indexes?
Before removing any index, test the changes in a development or staging environment.
- Duplicate indexes: Can be safely dropped as they offer no additional benefit over the identical index.
- Redundant indexes: Exercise caution as they may be used by specific queries. Analyze query performance before removing them.